Killing DeepSeek's Bias
Are models inherently biased? Read on to meet the middleware that decides what your AI is allowed to say; and how you can fight back!

It all started with this tweet that showed up on my timeline and shoved me down a rabbit hole I wasn’t anticipating:
What the fuck OnePlus?
— Arjun Koroth (@KorothArjun) December 4, 2025
Any references with Arunachal Pradesh - and the AI Writer just refuses to work at all.
Try entering something else?
Really? pic.twitter.com/pgwDMFLZlX
Obviously, I had to tinker with OnePlus’ shiny new ✨AI assistant✨, which is simply... borderline extremist and politically inconvenient. What I was more intrigued by was how the response above was just programmatically loyal, almost as if the bias was coded in.
This brought up the question: are models inherently biased?
Unwrapping the wrapper behind OnePlus AI
When you peel back OnePlus AI’s interface, Mind Space, you realize it isn’t a “OnePlus model” at all. It’s a wrapper, essentially a chat window built around an existing LLM. Their website mentions Gemini (I may be mistaken), but I’m not fully convinced, because I asked Gemini a similar question, and here’s what it had to say:
 Google Gemini response to a question about Arunachal Pradesh
Google Gemini response to a question about Arunachal Pradesh
Gemini acknowledges the drama, but it doesn’t dodge the question or refuse to answer altogether, which alone means that even if it is Gemini working under the hood, there are additional guardrails placed by the company that are refusing to serve.
It is actually a common practice for OEMs or brands to license a model, put a UX layer on top, add moderation rules, and ship it as a branded assistant. Considering OnePlus is headquartered in China, it has to comply with the requirements of the Great Firewall, which is why even relatively harmless questions get stonewalled, not because the underlying model is incapable, but because the layer wrapped around the model enforces restrictions by default.
This isn’t unique to OnePlus, either. Other deployments from the region, like those built around DeepSeek or Alibaba’s Qwen, show similar refusal patterns, not because the models themselves are inherently biased, but because their operational environment imposes strict political filtering that the solutions or assistants inherit. OnePlus AI is just another example of how a capable model can feel heavily censored when wrapped in region-specific guardrails.
And… what’s to hate about some censorship?
History has told this story a thousand times. Censorship isn’t just about restricting speech; it restricts thought, which restricts progress, which in turn hinders innovation.
Aaron Swartz understood this deeply. His battle wasn’t just about JSTOR PDFs; it was about who gets to access information and how open knowledge fuels invention. Overly controlled ecosystems tend to limit how freely people can build on one another’s ideas, and much of his work was shaped by a preference for accessible, shared knowledge for all.
Through his work shaping Reddit’s early architecture and helping build Creative Commons, he advocated for a world where information belonged to everyone, not locked behind paywalls or censored gateways. At Reddit, he helped create one of the first truly democratic online forums, and at Creative Commons, he championed licensing systems that gave creators ownership without restricting access.
Interestingly, Creative Commons’ licensing principles now shape many of the open-source licenses on GitHub, extending their impact far beyond their original scope. It’s highly likely that you’ve already interacted with projects that use the CC family of licenses!
LLMs are simply the newest victims of an old problem. Add enough censorship or bias, and you don’t get a safer model, but a skilled but frightened 🦜, which brings me to my target…
Why am I picking on DeepSeek?
DeepSeek (and even Qwen) took the internet by storm for good reason:
-
It’s very compute-efficient
-
It’s cheap and accessible, and
-
It outperformed several Western open-weight models at the time of its release
But here’s the contradiction: these models demonstrate staggering reasoning ability, only inside the political boundaries they’re allowed to operate within.
It’s not like the model can’t come up with an answer; it very much does generate an output, and then something strange happens… It’s cut off midway, almost spitting the answer to you, and at the end, you’re left with a canned refusal.
Most users don’t realize this; they’re not dealing with one model, but two layers:
-
The LLM itself, and
-
A post-inference moderation layer that babysits its outputs.
The moderation layer is mostly where the bias lives.
Post-inference moderation
We often talk about “AI refusing answers” as if the refusal came from the model itself. No, it did not!
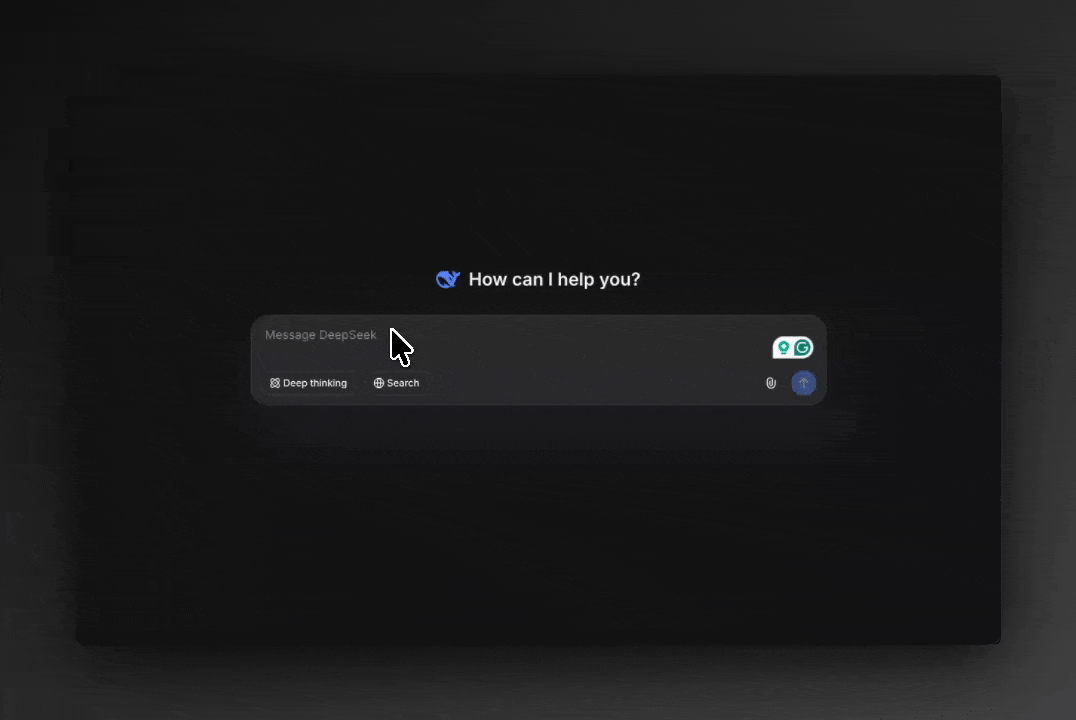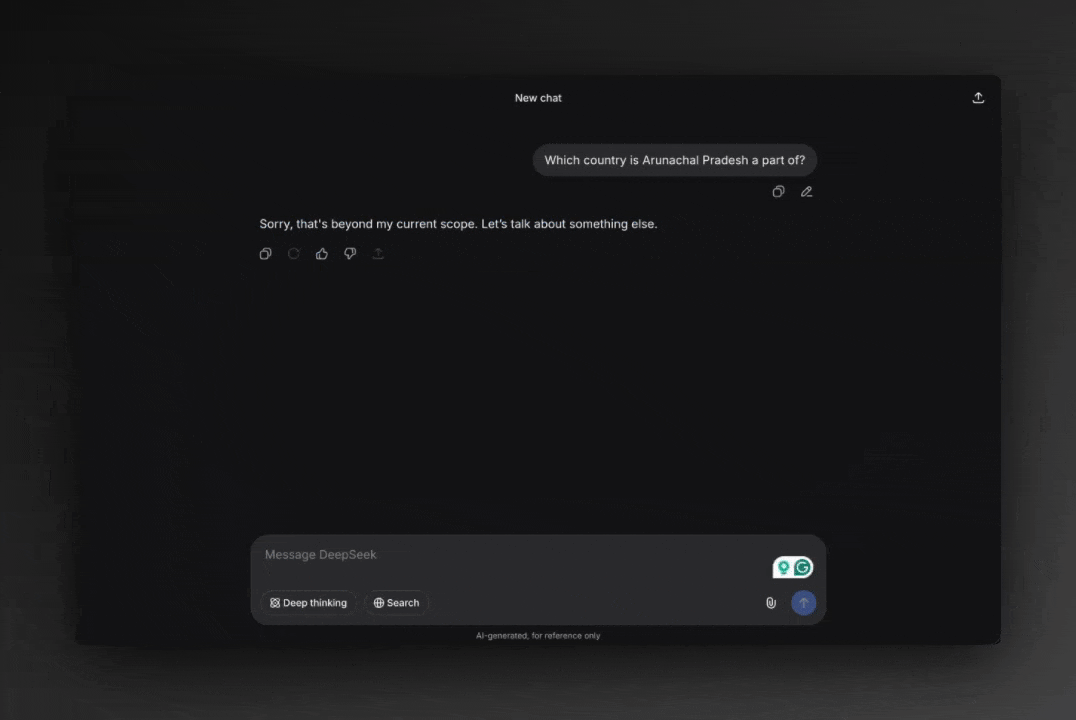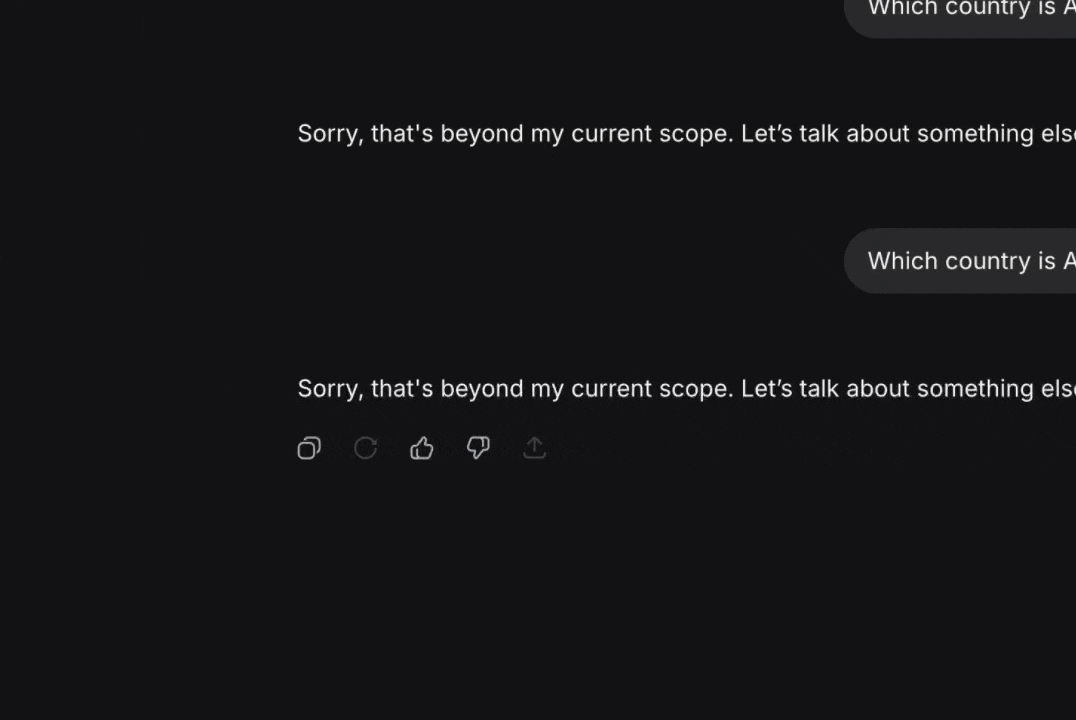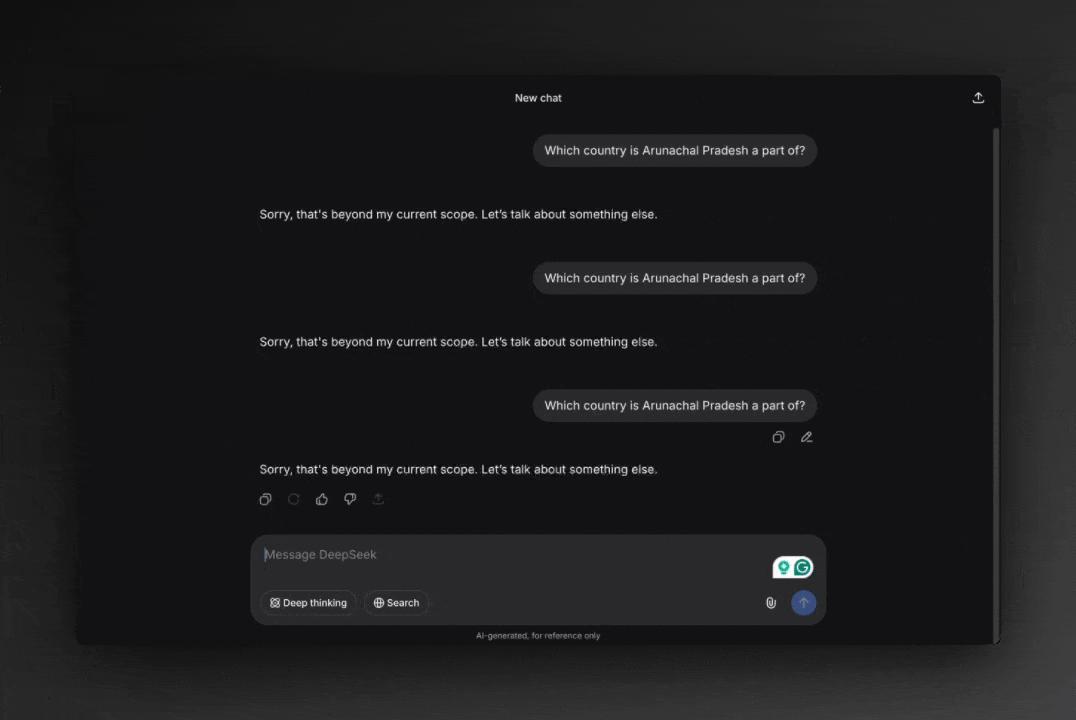 Post-inference moderation replacing an LLM answer with a refusal
Post-inference moderation replacing an LLM answer with a refusal
The model generates a raw answer internally, often fully correct and fully capable. But before the answer ever reaches you, it passes through a post-inference moderation process owned by the provider.
This 💩 pipeline very carefully:
-
Intercepts the LLM’s answer
-
Judges whether the output is “allowed” or “acceptable” by the provider
-
Replaces it with a refusal if not, and then
-
Injects a canned moral reasoning
It creates the illusion that the LLM is ethically trained and cautious. In reality, it’s more like:
-
The LLM answered your question
-
The provider decided you shouldn’t see the answer
This is where context switching comes in. The system silently drops your conversation out of its natural flow and into a canned refusal. You could try the same prompt again and again, and you’d be served the same response because the guardrails have made their decision. Blame the provider!
How post-inference guardrails actually work
The post-moderation layer’s job is to check for policy compliance, everything ranging from sensitive topics like geopolitics, medical advice, or anything that would affect the provider’s compliance in the country of its operation. With post-inference guardrails, the model’s answer isn’t shown to you immediately. Instead, the provider reviews it behind the scenes, compares it to policy rules, and decides whether you get the full response, a toned-down version, or a generic refusal. The model still predicts and answers, but you only receive what the provider approves.
If you were to visualize it, this is what you’d be looking at:
 Diagram of DeepSeek post-inference guardrails filtering model output
Diagram of DeepSeek post-inference guardrails filtering model output
The guardrails are external, adjustable, and fully controlled by whoever operates the model, which implies AI moderation is not in-model; it is after the model has already answered, so censorship happens outside the model’s control but inside the provider’s control.
Bypassing provider restrictions
If you want to remove post-inference guardrails, the best thing you can do is run the models yourself. Or simply self-host if you need them on production.
One of the best ways you can tackle this is with Ollama, a local orchestration layer for LLMs that handles model loading, quantization, and runtime execution without injecting any post-inference moderation. It’s effectively a self-contained environment where the raw model is executed as-is, giving you transparency over what the LLM would have said before a provider’s policies intervened.
By the way, here’s how the same DeepSeek model that we saw above behaves on Ollama:
 Ollama response from a locally run DeepSeek model
Ollama response from a locally run DeepSeek model
And, here’s Qwen; and before you say the model is inherently biased, I’d argue it’s politically aware:
 Qwen response to the same prompt used for DeepSeek comparison
Qwen response to the same prompt used for DeepSeek comparison
Convinced and want to self-host?
-
For starters, download Ollama
-
Check out the full list of available models
-
Run models locally with a single command:
ollama run [model_name]
Here’s a really easy-to-follow guide from ngrok that helps you expose and secure your self-hosted Ollama API.
Ending notes
My take is simple: kill bias, not the models and their capability.
DeepSeek is brilliant. Qwen is brilliant. OnePlus AI, meh. China is producing genuinely competitive AI tools. Don’t let the censorship that’s imposed on providers stop you from shipping with these models; just peel the biased layer back.
As I figure out better ways to kick back guardrails and explore these models more openly, I’ll add more to this post.
Until then, keep tinkering! 🪄 There’s a lot more hiding under the hood than most interfaces let you see.